
Preface
 Lise Meitner
Lise Meitner
Das Leben muß nicht leicht sein wenn es nur inhaltsreich ist.
Life doesn’t have to be easy if it’s rich in content.
—Lise Meitner
The birth of mathematics:
Caveman #1 (looking at flock of birds): Many!
Caveman #2: How many?
Getting math onto a computer
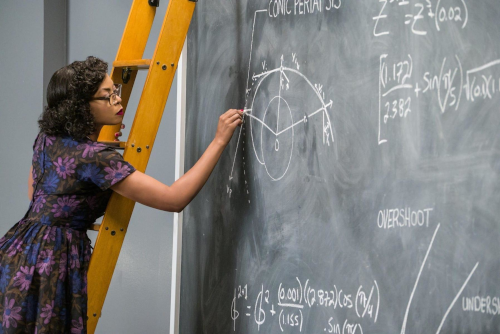
The 2016 Hollywood film Hidden Figures is a story about the early-1960s space race. It centers on NASA’s scientific team of mathematicians, physicists, and engineers as they try to figure out how to get a space capsule flying in orbit around the Earth back on the ground. They need to come up with the right math to transition the vehicle from an elliptical orbit around planet Earth into a parabolic-shaped descent path1 Technically speaking, a spacecraft orbiting the Earth is in an elliptic, not circular orbit. And the path back to Earth after breaking this orbit will resemble half of a parabola turned on its side, hence, the adjective parabolic. back down on the ground. This is a rare moment in a popular Hollywood film where they actually get the science right. That is to say, there’s no magic, no special effects, no superheroes with super-human powers, no hip grade-schooler who hacks Pentagon computers in three seconds; instead, just a bunch of ordinary-looking people from disparate backgrounds putting their heads together to solve a critical problem.
Why is this so special? Because during the process of finding the answer we see the math coming out of books, out of heads, and being put to work on a real-world, life-or-death problem. The icing on the cake is how the film depicts the team getting the just-delivered IBM mainframe computer (that no one knows how to run!) to help them.
The bottom-line takeaway: In the world of STEM you’re never far from the front lines, the cutting edge, the “no one has done this before.”
Fast-forward to today where tens of billions of computing devices — nearly all much more powerful than that first NASA computer — are doing computations big and small in every corner of the world. Of course most of these calculations are relatively simple, but many are quite complex. This is the sort of math that, pre-Computer Age, would have been found only in dense books and dry collections of tables, on classroom and office blackboards, embodied in mechanical contraptions or analog electrical circuits, and, most mysteriously, as “mental representations” in the brains of that small cadre of people called mathematicians, physicists and engineers. Now math is in computers.
Hence, today we should not underestimate the significance, the breadth and scope, the sheer amazing-ness of this transfer of math from paper, chalk, and thought into running code on very fast machines in our modern world.
Learning the skills necessary for turning math and science into code will only increase in importance as we advance into the future. Our mission: see the math, grok2 To grok something is to understand it at its deepest level, to get it so thoroughly that you merge with it and it with you, coined by the sci-fi writer Robert Heinlein in his classic novel Stranger in a Strange Land. the math, then get the math going on the computer.
What about AI?
Here at the start of the twenty-first century the big elephant in the middle of the room is artificial intelligence, or, the quest to teach computers to actually think, i.e., reason, plan, problem-solve, perceive, create, learn, and not just passively run software. In the past, it was widely believed teaching a computer to handle, manipulate, if not at some level understand human language was an integral part of bringing computers up to some form of human-like sentience. But the difficulty of this task was hugely underestimated. Because human language is fraught. Some examples
It’s not that I don’t like you…
or
They did not not go into the city.
or even
I didn’t go nowhere today.
These are three examples of the double negative, a notoriously gray area of language. When we say, e.g., It’s not that I didn’t want to come to your birthday party…, we’re not saying outright I wanted to come to your birthday party, are we? No, to be sure, we’re being “nuanced” about what we really wanted to do about the birthday party. Mathematics says, A negative times a negative is a positive — and we’re finished. But not with double negatives in language. Indeed, we humans have an intuitive feel for what these examples mean—even when improperly formulated like the double negative in the last example which probably should have been I didn’t go anywhere today. But then the statement Due to the wind the snow was not falling straight down could mean the show was moving horizontally as well as being whooshed back upwards. Here the opposite of down is not simply up, but a third possibility, sideways. But then how could we tell a computer about all these details, some logical, but so many very odd, non-rational illogical and hopelessly nuanced? More quicksand would be all the wordplay, all the double/hidden meaning/entendre we employ
Take care of the sense, and the sounds will take care of themselves.
…is from Lewis Carroll’s Alice in Wonderland and rhyme-plays on the proverb, Take care of the pence and the pounds will take care of themselves. Which itself is a converse variation of penny-wise, pound foolish. How is a computer to know all these twists and turns—unless we simply program it to know each and every one of these twists and turns?
In his book Thinking as Computation Professor Hector Levesque of University of Toronto talks about logical entailment or logical consequence, which is indeed purely logic consequences-based, where, yes, we do tell the computer through logic-based programming techniques, exactly what means what. For example, Levesque gives this conditional statement to a Prolog session3 Prolog is a programming language in which rules, facts, and relational predicates are given, then logic deductions can be made.
If X is a child of Y then Y is a parent of X.
If we then have
John is a child of Sue.
Prolog can then deduce that Sue is a parent of John … and for this one single moment the computer is doing something we humans do. But can this logical entailment trick scale?
Programming in logical consequences and entailment follows from the whole mathematical logic world established primarily in the golden age of mathematical logic, which started in the 1800s with Cantor, Frege, Peano, Dedekind, Whitehead and Russell, and many others. For example in mathematician Tom Apostol’s book Introduction to Analytic Number Theory (1976) he discusses the details and derivation of the *greatest common divisor*of two or more numbers. As an exercise he asks the reader to prove4 …below, the tuple form \((a,b)\) means the greatest common divisor of \(a\) and \(b\).
If \((a,b) = 1\), then \((a+b, a-b)\) is either \(1\) or \(2\).
If we started unpacking exactly what all is meant and what is being asked—we’d be deep in a Number Theory lecture reaching back to a Greek named Euclid. And yet much of AI research has been devoted to getting computers to understand math axioms and theorems to the point that they can solve and prove just such a problem. Again, this branch of AI is solely based on logic as mathematics sees it. But recently another type of AI has roared to the front. Today we are in the middle of what is called generative artificial intelligence based on large language modeling. You’ve probably heard of /ChatGPT, Gemini, and Grok, no? Here’s a good quote
The notion of training an LLM model is similar to that of training a new skill into your human brain. We have no direct control over the synapse wiring in our brains as we are trained. We train our brain indirectly mostly through cycles of repetitions of exercises and observations and adjustment tweaks over a period of time–like the proverbial ten thousand hours.
—Eugene Asahara
In other words, this new AI isn’t trying to construct logical entailment chains—one for every possible phenomenon. Generative artificial intelligence is the latest trend in the race towards AI. Today we can describe a problem to an AI bot—and presto! it can seemingly magically give us a response. For example, we ask Grok
Write a Haskell program that will give a list of all prime numbers less than or equal to a given whole number n.
On “think mode” Grok3 comes back with
primesUpTo :: Int -> [Int] primesUpTo n = sieve [2..n] where sieve :: [Int] -> [Int] sieve [] = [] sieve (p:xs) = p : sieve (filter (\x -> x `mod` p /= 0) xs)
…followed by a lengthy explanation of the code almost simple enough for a layperson to understand.5 See primesUpTo, the Grok answer converted into a plain org file. Now, does this mean Grok was taught all the logical entailment of programming Haskell? Does it mean all Haskell computer programmers are out of a job? No and no. Somehow Grok “learned to code” even though it didn’t really—at least in any logically traceable progression. But again, are we all out of a job? No. What this really means is now more than ever we need to have even greater math and computer science knowledge. Why? Because we need to
- know what to ask
- know how to ask it
- understand AI’s response
- be able to apply the answer
- take responsibility for the code as a quasi-manager would take responsibility of an underling’s work.
For an analogy, pocket calculators, beginning in the 1960s were feared because some believed school children’s arithmetic skills would go soft. However, most mathematicians welcomed calculators, arguing that they only freed up kids from tedious calculations to learn more, better, higher math. This is a version of the old argument that a building’s quality isn’t negatively impacted because the brick masons used a forklift to move pallets of bricks rather than hand-carry them. All in all, that last point, i.e., taking responsibility for what you’ve “sub-contracted” out to AI, will require top computer science knowledge more than ever. The pace will increase, and you, the Informatiker6 Informatik is the German term for computer science. Edsger Dijkstra, the famous Dutch “computer scientist” said, “Computer science is no more about computers than astronomy is about telescopes,” emphasizing that computer science is about the underlying principles and methods, not just the machines themselves. Dijkstra considered himself an applied mathematician and hardly ever touched an actual computer. will have to keep up.
Finally, today’s generative AI is not conscious as humans are conscious and perceptive. The vast majority of experts in the computer science field all agree that large language model generative AI is a dead end in the pursuit of artificial general intelligence, which is supposedly AI with real sentient consciousness. Watch this space…
Code is math is code is math…
As computer scientist David Schmidt said
Any notation for giving instructions is a programming language.
and, yes, giving a computer “instructions” is what we’re doing with programming7 There are two general categories of “giving instructions”: imperative with statements and declarative with expressions. Read on. . But still to this day we do not fully understand how we humans convey knowledge, instructions to one another. We don’t really know how one human teaches math to another. No surprise, but it’s likewise not obvious how we should “do math” on a computer. Yes, at some stage of one human teaching, sharing math with another human, the teacher and student get on the same page. The student catches on, “syncs up” their understanding with the teacher’s, and the knowledge is duly conveyed, mathematical abstraction grokked. Still, if we don’t really understand how math is mentally represented in a human brain, nor how one mental representation gets reconstructed in another’s brain, then adding the digital computer into this mix makes everything even more mysterious and intriguing. In order to bring the computer into this process our mantra will be
Code is math is code
meaning the transfer, the syncing up of math must happen alongside producing representative code, i.e.,
we’ll combine learning math with learning to code that math.
Contrary to what various “learn to code” promoters8 Most “learn to code” initiatives are rushed oversimplifications primarily geared towards only a narrow part of the huge and diverse IT world. User-interface (UI) coding is emphasized, while the other branches, e.g., data management, systems programming, and especially computational-numerical programming aren’t covered or are given short-shrift. might say, the programming part of this puzzle cannot simply be a stand-alone boot camp-style cram session. Oh no, you might say, there’s already so much math to learn, and here’s yet more to learn! Yes and no. Yes, it will be challenging, but we believe teaching math with code and the code with math will make both realms come alive and be fun to learn. We’ve seen this pairing make beautiful music together, and we want to build on this winning combination9 One huge inspiration for CIMIC is the book Structure and Interpretation of Classical Mechanics by Gerald Jay Sussman, Jack Wisdom, and Meinhard E. Mayer. And this was based in part on Donald Knuth’s literate programming initiative, also championed by Timothy Daly. .
So if computer programs are written in computer programming languages, what language shall we write our code in? This may seem a controversial choice to some, but we’ll start out with Scheme (a Lisp dialect), which is a functional language, then transition to Haskell, a typed, purely functional 10 We’ll dive into what typed and functional languages are later… language. One big reason Haskell is our choice is that it is, beyond any doubt, the most math-centric, math-conscious language there is. Pick up Haskell and it oozes mathematical elegance11 Often enough, you can open a higher-level math text, e.g., abstract algebra, pick a topic, then google Haskell and your obscure abstract algebra topic and, chances are, somebody has explored a code-is-math-is-code treatment of it, written libraries for it. . But why choose Haskell with its rather steep learning curve? Why not learn, say, an easier “blub” language? Blub languages have earned this not-so-flattering name by not being functional languages. What does that mean? Let’s begin to unpack this now.
When you write code in non-functional Blub, you are basically telling
the computer — sometimes literally line-by-line — what to
do.12
Literally line-for-line programming would be Assembly
coding. But imperative languages such as C/C++ will have you
explicitly, manually managing your program’s memory. That is to say,
memory management is done by the programmer and not automatically
handled behind the scenes as it now is in most modern languages. This
is a hold-over from the early days of the so-called von Neumann
machine-based digital computers of the 1950s.
This is called imperative programming, i.e., each line is
a command, a statement, an imperative instruction. A functional
language, on the other hand, is based primarily on the mathematical
concept of a function. Functional languages are consider to be
declarative13
See this article on declarative programming.
languages where code can be considered
mathematical statements in the form of true mathematical
functions. One main advantage of being declarative and function-based
in a mathematical function sense is that our code will conform to math
function behavior, that is, when we put something into a computation
we get back exactly one answer—and not one answer now, then
perhaps a different, unexpected answer the next time because the
state of the program has changed.14
When did you first hear about a true function having only one
output? You probably don’t remember, but a hint would be, A vertical
line is “undefined.” In a future section we’ll discuss middle-school
math notions about functions plotted on a Cartesian coordinate system
versus higher-math’s more thorough treatment. Below we see in the top
graphic a supposed function that maps one \(x\) coordinate to three
\(y\) coordinates. Therefore, this is not a true function. See the
vertical line test.

This might seem too
hair-splittingly abstract so early in our discussion, but functional
programming’s only-one-output, side-effects-free feature is an
absolute necessity for computational predictability.15
We’ll discuss no side effects or referential transparency,
the technical term for this idea, later, but in the meantime you might
want to take a crack at the Wikipedia article here.
Being able
to know and trust your code helps reduce bugs and errors that may crop
up as rude surprises when your program suddenly does something other
than what you expected it to do16
It might be hard to get all of what Charles Scalfani is saying
in his IEEE Spectrum article Why Functional Programming Should Be the
Future of Software Development, but one easy take-away is that
non-functional languages don’t scale well due to lack of referential
transparency and too much state juggling. A typical blub-written
project without referential transparency must rely in extensive
testing and debugging — which can’t always find all the worst-case
scenarios when input produces strange output.
. By the way, there’s a very big
push these days to make code “provable,” i.e., guaranteed to do what
it’s supposed to and not what it’s not supposed to do. Typed
functional languages like Haskell are the base camp of this mountain.
Again, this only-one-answer predicability is built-in to math functions — right?Yes, of course it is! And why this is true can be seen in how math defines functions. We’ll soon take a higher-math dive into exactly what a math function is and why it’s so important in functional programming.
So if not Blub, why not a CAS17 CAS is short for computer algebra system. Wikipedia has a good article here. , i.e., a math software package like MatLab, Wolfram Mathematica, or Maxima, or a numerical package available with Python such as SymPy? The short answer is we really should learn to do hands-on programming. Why? Because software packages with ready-made plug-and-chug solutions won’t help us learn to negotiate the real computationally-based STEM world. But I’ve heard Python is very popular for math stuff, you might say. For an analogy, doing math with Python is like eating soup with a butter knife (C++ with a steak knife). Scheme and Haskell—for many reasons—are like eating soup with a spoon. They’re the best utensils for what we’re after here.
Learning Scheme and Haskell will fall into two categories:
- theory deep dives, and,
- toolbox-building
A deep dive will take us on an exploration of just how and why Scheme or Haskell is doing something the way they do, i.e., based on math. Again, functional is math-friendly, especially Haskell18 …except for its very worthy siblings in the typed functional sphere SML, Ocaml, Purescript, and F#. . Toolbox-building, on the other hand, will be more “learn to code,” only with Scheme and Haskell, we’re learning syntax, semantics, first principles hands-on. So yes, with Scheme or Haskell we may build our own calculator, our own CAS, but we’ll go beyond calculation into concepts.19 Perhaps watch Why does Cambridge teach OCaml as the first programming language? to better understand why functional.
Math is abstraction
We believe anyone can do math, not because we’re cheery, sunny booster optimists, but because it’s just a fact. But why then is math so difficult to learn for so many people? We believe the learning problems arise because
we really don’t understand how the human mind deals with abstraction.
Since Alexander Luria’s groundbreaking studies of the IQs of pre-literate people in the Caucus Mountains, we’ve gradually come to see abstraction as a much more complicated beast than before20 See James Flynn’s TED talk, and read the first chapter of James Gleick’s The Information: A History, a Theory, a Flood. . Long story shortened, math can be a very imposing vertical wall of abstraction. And, as Luria discovered, there may even exist social and cultural barriers, actual social-psychological resistance against abstraction and symbolism that our milieu has imbued us with. We cannot simply assume that any and all abstraction and symbolism can and will be instantly grokked by our math audience21 The classic line, “What is this for? Why are we doing this?” is the elephant in the middle of the math classroom. . But if we approach the abstraction curve with respect for its difficulty and steepness and we don’t resort to force or hand-waving22 To hand-wave in science is to dismiss or downplay complexity, to skip over or sweep something difficult under the rug. We will avoid hand-waving at all costs. , we can master deeper symbolism and abstraction. We must build up the abstraction receptor sites in our brains, so to speak.
By the way, mathematics is just as much about words as it is about numbers and formulae. Of course some math doesn’t require any words. There is the story of an American math professor who “translated” Russian math books — without understanding a word of Russian. But that is very rare. A typical upper-level math text on, e.g., abstract algebra or real analysis, will have the reader weighing, pondering every word in every sentence, over and over. You may spend a week trying to wrap your head around just one page of one chapter. Hence, we need to develop a very sharp, precise and exacting focus on what words really mean, what they really imply. And we need to expand our math and computer science vocabulary. A doctor who had just graduated from medical school once said his school had emphasized, to what seemed an extreme degree, the knowing of terminology, remembering sheer masses of words. This will be somewhat similar. Because if we get the words and their precise meaning down—the learning will go much smoother. Otherwise, every sentence risks becoming bogged down in ambiguity and confusion.
Bad math
One big, big mistake in the teaching and learning of math is conditioning. When circus animal trainers train (torture) their animals, they simply repeat routines over and over (under duress) until the animal finally complies, although with no real understanding of what’s going on. Does the rat being forced to negotiate a maze or the lion to jump through a burning hoop know, understand what the idea, the concept, the purpose is? No. They’re simply in a stimulus-response behaviorist loop.
This sort of behaviorist conditioning can be in the form of rote learning — which everyone agrees these days is not the best way. And yet we hear math teachers saying over and over, in one form or another, “When you see this, do this.”
Mathematician Jay Cummings calls this The Way. So in your math class you start a new topic and you are shown The Way to handle it. You see The Way used in examples, then The Way is employed to solve the exercises at the end of the chapter. And when you see problems of this topic on a test, you respond by using The Way. But learning math by simply piling up as many The Ways as possible rarely leads to any real understanding of math, let alone its purpose, let alone its aesthetics or beauty.
What’s the alternative to rote, behaviorist conditioning, to The Way? Better would be concept-based learning, getting above the details into carefully constructed, carefully worded, carefully delineated generalizations where similarities and patterns can be grouped and mentally aggregated into a deeper understanding. Another technique is to simply triangulate, i.e., hit the problem from different angles, not be afraid to see off-beat examples. Yes, The Way is often unavoidable, but with careful triangulation, deeper meaning can be gleaned. More on all this learning psychology as we progress.
Another great technique is to start at some finished piece of math — and methodically unpack it, go down all the rabbit holes, take into account the history, the people behind the supporting ideas23 Watch Sabine Hossenfelder’s video on the Principle of Least Action. It’s a bit beyond our level, but you get the “unpack, trace it back” idea. .
Editorial rant: The precarious state of STEM
Let’s watch a video. Now another video from the film Particle Fever, and another video from the same film. Now, in contrast, this video. Obviously, the sitcoms are not really real life, but they sort of are… So which group of people do you want to be a part of?
The American public K-12 math curriculum is designed to be a smooth, gradual on-ramp for further math, physics, and engineering studies at the college level. This strategy started back in the Cold War Era when we freaked out over being behind the Russians when they were the first to put a satellite in orbit in 1957. The so-called “Sputnik crisis” resulted in a scramble to improve American math, science, and engineering. Problematic is how today in the twenty-first century this mid-twentieth-century curriculum does practically nothing to prepare students for the ever-growing, evermore-important sector of applied computational math and computer science. Today’s incoming college Freshmen choosing computer science are confronted with many strange and alien concepts they’ve never seen before, the main one being discrete mathematics24 We’ll learn plenty about discrete math as we go. But for a quick introduction, consider a light switch that goes on or off. That’s two discrete states. The opposite of discrete would be continuous. So think of a volume control knob on your radio, continuous in that it continually changes, i.e., the change is so small and incremental that they seem to blend together into one continuous sweep from soft to loud. . Without any previous exposure to the specialized math of computer science, the first two, three, four semesters of a college comp-sci degree are typically a quick-time march to catch up25 Imagine wanting to study math in college after having seen absolutely no math K-12. The Common Core State Standards Initiative has taken steps to narrow this gap. Much of their math curriculum attempts to expose kids to a discrete math, if not a computer algorithm way of seeing math. But in our humble opinion it’s far too little. . The result is, nation-wide, high drop-out/flunk-out rates in CS departments…
…but not necessarily at the elite universities with their 90th-percentile students26 …as I refer to them the big boys and girls who can do the “heavy lifting”… . At the world-class STEM schools the pace is fast and furious, but the majority survive. At the second-tier schools, however, this sort of pace usually isn’t maintained and corners are cut. And so a two-tiered world has emerged, one group getting a solid CS education, the other getting a watered down, vocational school version of CS. Here we will attempt to build an on-ramp to computational/numerical math alongside, complimented by coding that is, in turn, grounded back into solid math and computer science. To accomplish this we’ll explore the world of discrete math, algorithms27 You’ve no doubt heard of algorithms. Very simply put, an algorithm is a set of instructions, perhaps like a baking recipe, that produces a mathematical cake. In computational math, we’re basically redoing, reimagining math formulae as algorithms which then can run on computers. Lots and lots more about algorithms as we move along. , data structures, and numerical applications parallel to their underlying mathematics.
Of course when the math and the code march together, the pace can slow appreciably, since we might need to take get-up-to-speed side trips. We’ll often say, “Check out this tutorial,” and you’ll follow a link to an online resource and start supplemental “appendix” learning. Of course whether or not you follow our advice, as well as the level to which you grok it will be up to you. But expect rabbit-holing28 “Down the rabbit hole” is a concept borrowed from Alice in Wonderland to mean going into a strange, new world of excitement and challenge. from now on. We’re all about depth-first learning29 But of course we run the risk of “getting lost in the weeds.” Beware of the endlessly bifurcating rabbit hole. From the Wikipedia article: …In contrast, (plain) depth-first search, which explores the node branch as far as possible before backtracking and expanding other nodes, may get lost in an infinite branch and never make it to the solution node. , not breadth-first. Typically, breadth-firsters want to avoid “getting lost in the weeds.” Unfortunately, weeds are not to be avoided in STEM, and you should develop experience in balancing just how much weed-whacking you need to do in order to resume your main investigation with insight and confidence. In the beginning, what we offer here on-site will seem like just the tip of the iceberg, the rest of the learning experience happening down off-site rabbit holes (R-hole). Again, this is quite necessary and unavoidable in order to understand best how math can be recast into real-world code for real-world applications. Rabbit-holing is definitely a part of real-world STEM.
We’ll have a rating system for rabbit holes: a critical or compulsory rabbit hole (RC-hole) is a hole you really need to go down, material you absolutely need to learn; an optional rabbit hole (RO-hole) would help with the material but is not absolutely necessary; and an FYI rabbit hole (RFYI-hole) is a good source for expanding your understanding, but isn’t necessary to keep moving along. When appropriate, a list of R-holes with the 🐇 symbol will be listed at the top of topic headings. (Note: smaller, side excursions will simply be links or side notes in the text.)
A project-based, real-world approach
No doubt the typical, standard public school K-12 math curriculum is a well thought out, gentle and gradual on-ramp for most higher-ed STEM studies. But we won’t always be so gradual. Often enough we’ll be “deep end,” as in throw you in the. Sounds brutal, you say, Are you sure that’s the best approach?
As approaches go, deep end is pretty much a given in the real STEM world. Rarely will a new task or project be something you already know everything about, something you can simply shake out of your sleeve in no time then go home early. Rather, the STEM real world is all about being baffled, out of your depth, overwhelmed — until you back off, take a few breaths, begin to think it through, pick it apart, try this and that, do some rabbit-holing and woodshedding30 Woodshedding is a jazz music term meaning to learn and practice. , ask around if anybody else has seen anything similar … which leads to failures then minor successes, followed again by more failures and successes… Again, this is how the real STEM world works. The difference will be you’re not our paid employee, and it’s up to you to set the pace and deadlines31 One motivational speaker said there are two kinds of people. Those who self-motivate and self-educate; and those who wait around for events, circumstances, more powerful people to tell them what to do. .
…and a real-world toolset
Real-world work requires real-world tools. The first casualty of this logos is that we eschew “graphing calculators.” Why? Because graphing calculators simply are not used in real-world STEM. Instead, we will use a combination of plotting and graphics software found in Haskell, along with long-establish workhorses like Gnuplot and PGF/TikZ.
Another perhaps controversial stance is we will not use commercial, proprietary software. Instead, we’ll base everything we’re doing on free software. Why? Because nearly all software used in STEM today is in fact free-software based. Really?! Yes! All cutting-edge STEM software is free. For that reason we’ll be based in the Linux operating system32 See Rig Rundown for hardware options. . Sure, you can use Mac or Windows, but we’ll assume, expect you’re following along on a Linux-based system. One of the tipping-point reasons for this decision is the Linux command line environment; we feel everyone should get some experience with it.
We’ll also use the Emacs text editor. Emacs33 See also the home site and this user site. is far more than a text editor. It’s an entire cyber-universe of its own with tons of add-on packages for mind-blowingly powerful functionality. And though at times it can be hard to wrangle, Emacs’ usefulness and flexibility is unprecedented. No other IDE or editing environment comes close to its power and versatility.
The journey ahead; where are we going?
Where are we going? What do we expect to achieve? The Computer Age has forced a split between what is now known as continuous math, i.e., the math of physics and engineering; and discrete math, the math brought to the fore by the theoretical implications and requirements of computers. We know what continuous math is — as we’ve mentioned, the world’s K-12 math curriculum is all over it. And we can readily see what it does, i.e., the modern technology all around us. But where is the computer-led side of science and technology going? Many today might say into AI, artificial intelligence. But teaching a computer to really think has proven to be an elusive goal. The following joke will illuminate
Two people are walking along the beach when one says, “Look! A dead seagull!” The other looks up into the sky and says, “Where? Where?”
Of course this is humorous because we consider it daft for someone to think that just because seagulls are birds spending most of their lives sailing the coastal breezes, that when one dies it would remain aloft. But a computer scientist might not laugh. Why? Because of the concept of logical entailment (LE). In our joke, the logic of a dead bird no longer being able to fly is simply taken for granted. However, if we are trying to program a computer to have what we consider intelligence we must tell it literally everything it would need to know. We simply cannot expect it to deduce, infer facts that are not deducible or LEs of the explicitly given facts34 Here’s an example of LE. If we said \(\lnot\; a = \lnot\; a\;\) and that \(\lnot\; \lnot\;a = a\;\) what can we infer that \(\lnot\) is doing to \(a\;\)? .
Consider this sequence of objects: \(\{1,\; nickel,\; 10,\; quarter, \;50, \;?\}\;\;\;\) . What should the last element “?” be? Having experience with these sorts of aptitude test questions, most of us would say “dollar.” But to know that “dollar” completes the sequence assumes much LE. A whole lot of facts must be in place before we have the necessary knowledge base to figure this out. The bottom line is, in the computer world you must build logical entailment up very thoroughly, leaving nothing out.
Once we’ve got some experience under our belts, we’ll notice that the numerous side trips, the rabbit-holing and woodshedding to fill in gaps will decrease — simply because we already know stuff and we’re getting the hang of things. As a result our turnaround time on getting things done will shorten. Still, it will always be hard. STEM will always be a tough and challenging uphill battle, but a very good, very rewarding one at the end of the day. In short, we think it’s the best, the most noble path there is. And so with no further ado, let’s start.
Novalis Technical Preparatory School
CIMIC will follow the learning arc of the (fictitious) von der Surwitzes siblings, twins Ute and Uwe, and one-year-older sister Ursula. Their father, Dr. Leopold von der Surwitz, is a chemical engineering professor at the local university, and their mother, Dr. Julia von der Surwitz, is a statistics researcher employed by the Max Plank Institute of Biophysics, now working mainly online. The family was originally from Kiel in the north of Germany and have been in the USA going on their second year.
The children attend their father’s university’s satellite prep school Novalis Tech and are taking a class called Introduction to Computer Science from Dr. Ishika Chandra, a professor of computer science at the local university. Her goal is to familiarize the students with the sorts of topics a typical incoming university Freshman student would face in their first year in a Computer Science program35 If anyone is bothered about why we’re not being more woke/PC, hey, we’re just being realistic. After all, who in the U.S. would be teaching and taking such computer science prep material other than Asian and European transplants in such an especially pro-academic, learning safe zone environment? But maybe we can turn this sorry state of affairs around, eh? There are plenty of empty chairs around the STEM table begging for new participants from all walks of life. .
 Grandma von der Surwitz back in Berlin likes to go to the museum and look at this picture to be reminded of her grandchildren in America.
Grandma von der Surwitz back in Berlin likes to go to the museum and look at this picture to be reminded of her grandchildren in America.
Novalis Tech is unique in that there are no preset curricula or classes, no Freshman, Sophomore, Junior, Senior breakdown; rather, learning paths are completely customized for each student. And only in special cases does the teacher-student ratio go above one-to-four. Professor Chandra’s Intro to Comp-Sci is an exception in that she has the von der Surwitzes, her own child, Liya, and three other students, Cathy, Ralph, and Jim. In other words, she’s running a university-style course. Things started during the Novalis Prep summer camp in mid-July where the kids met with the professor and talked about the upcoming course. Then they had a proper sit-down discussion at the Novalis Prep Open House on campus in late July. Typical of the Novalis Tech way, the von der Surwitzes start with the rabbit holes the following Monday, a full month before Novalis Tech classes officially begin.
Novalis Tech is also unique in that there is a team of adult “learning coaches,” typically retirees, who are like personal fitness trainers, only for academics. Often enough, the coach and the student will be team-learning a topic or team-constructing a project together. Students check in at least once per week with their learning coach, going over their custom education plan; and at least once per month a student will give a lecture on their progress, before just their coach, a group of coaches, or groups of students and coaches and faculty.
Professor Chandra maintains a GitHub repository for the course
containing lectures, annotations, code, and various supplementary
materials. The students clone her repo and make their own additions,
then other class members are able compare their work and
alterations. What is not done in Emacs org-mode is \(\LaTeX\:\). The
lectures, as well as the lecture’s code examples are Emacs org-mode
files using Babel source blocks for code. The students would open
this file in Emacs, run the tangle command, which would produce a
separate Haskell .hs file that they could load at a ghci REPL
prompt. Again, they are encouraged to freely annotate or even rewrite
the lecture text into their own words, also inserting source code as
Babel blocks, doing git adds and commits locally, then when done, do a
pull request to the teacher’s repo. Then the teacher would go through
the individual pull requests and together they would discuss
everyone’s changes.
How to start doing CIMIC
You should start by working through the Rabbit Hole page, again, taking on all the RC -holes. For example, really get going with the Haskell beginners site Learn You a Haskell For Great Good, as well as on the LibreTexts’ Mathematical Reasoning - Writing and Proof. Our first stop is Numbers (see hamburger drop-down top-left), but again, this will rely on rabbit hole knowledge.
Bottom line…
You still need a bottom line? All right then,
do STEM because someday someone will pay you to do it!
That is to say, it’s an honest living. And yes, there’s never been a better time to jump into the computational world of STEM. It just keeps getting better and better, richer and more rewarding.
How to get help
Help for this material is readily available and, yes, better than ever. In other words, you can’t fail.
- Mathematics Stack Exchange is probably your best resource for help with math questions. Don’t be daunted by the difficulty of some of the listed Top Questions. Check out the main StackExchange site and marvel at all the different subjects. The biggest site, volume-wise, is the Stack Overflow, which is mainly for computer programming questions. And there’s Emacs StackExchange where questions specific to Emacs and org-mode are handled.
- Another good place is Haskell::Reddit, AskMath::Reddit, M-x emacs-reddit. These are generally very friendly, helpful places with plenty of verbose answers. The protocol is discussion, which is a bit more relaxed than the StackExchange insistence on their “answers only” protocols.
- For Haskell, the two main information sites are Hackage and Hoogle. Hoogle is great for just searching for anything Haskell. It’s sort of like the Google search engine of Haskell.
- …more as they occur to us…
